Hermes изнутри: архитектура автономного AI-агента в продакшене
Технический разбор архитектуры Hermes от команды RubikBot: пятислойная система, агентный цикл, модель памяти трёх уровней, библиотека 87 навыков, мульти-арендность. Уроки полугода работы в проде и сравнение с Claude Code, OpenAI Swarm, AutoGPT.
Этот разбор описывает архитектуру Hermes — автономного AI-агента, который работает в продакшене RubikBot и обслуживает тысячи запросов в день. Если вы — инженер, архитектор или технический руководитель, который думает о собственном AI-агенте или выбирает между готовыми решениями, эта статья даст ответы на три типа вопросов:
- Какие архитектурные компромиссы стоят за продакшен-агентом и почему мы выбрали именно их
- Чем подход Hermes отличается от Claude Code, OpenAI Swarm и экспериментальных AutoGPT
- Что сломалось за полгода в проде, как починили и какие проблемы остаются открытыми
Без маркетинга, без «инновационности», с конкретными цифрами и кодом конфигурации.
Контекст: чем агент отличается от чат-бота
Если вы зашли с поискового запроса «архитектура ai-агента» — нужно сразу зафиксировать терминологию. Эти слова часто путают, и потом непонятно, о чём речь.
Один запрос — один ответ. Между ходами нет состояния. Не может сам решить «сначала прочитать файл, потом запустить тест, потом исправить код». Например — ChatGPT в браузере, GigaChat, YandexGPT.
Чат-бот плюс агентный цикл: модель планирует шаги, исполняет инструменты, проверяет результаты, решает что делать дальше. Hermes, Claude Code, OpenAI Swarm, AutoGPT — все сюда.
Сердце любого агента — агентный цикл. На псевдокоде это выглядит так:
1. PERCEIVE — прочитать вход пользователя и контекст
2. PLAN — разбить задачу на подшаги
3. ACT — вызвать инструмент, запустить навык
4. OBSERVE — прочитать результат
5. EVALUATE — получилось? что дальше?
6. GOTO 2 (пока не готово или не застряли)
Внутри этого цикла спрятаны все архитектурные решения, от которых зависит — будет ваш агент рабочей системой или экспериментом, который виснет на пятой итерации с галлюцинацией аргумента инструмента.
Архитектура Hermes — пять слоёв
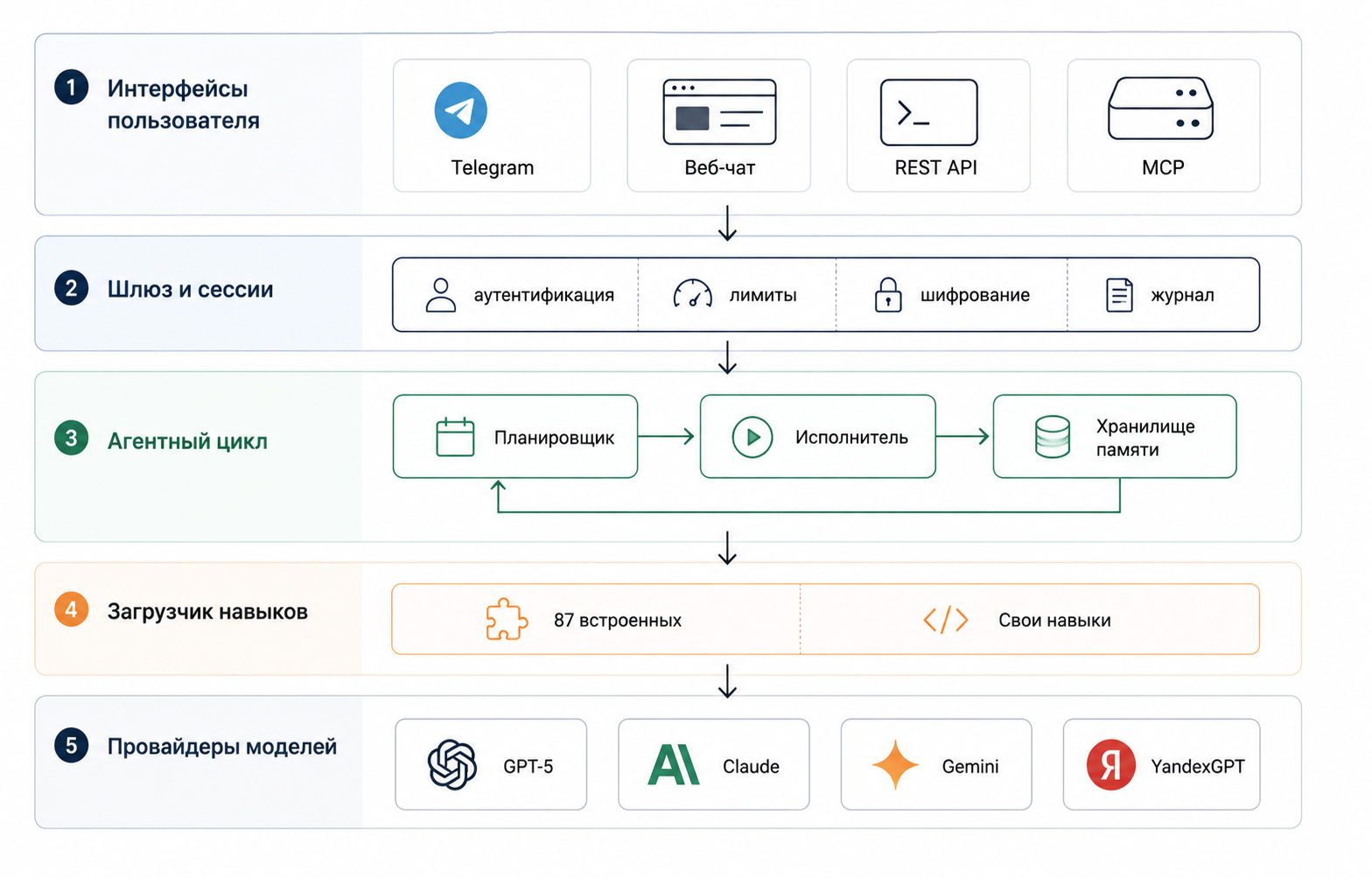
Слой 1. Интерфейсы пользователя
Три точки входа в один и тот же агент:
- Telegram, MAX — через обработчик веб-хуков (
hermes-telegram-bot) - Веб-чат — через постоянное соединение (
/app/hermes/chat) - REST API — программный доступ (готовится во второй фазе)
- MCP-сервер — для сторонних клиентов (Claude Desktop, Cursor)
Все четыре подключены к одному хранилищу сессий в SQLite. Это даёт непрерывность опыта: задал задачу в Telegram, MAX, увидел результат в веб-интерфейсе.
Слой 2. Шлюз и сессии
Перед самим агентом стоит шлюз, который делает четыре вещи:
- Аутентификация — проверка API-ключа арендатора или совпадения Telegram chat ID
- Ограничение запросов — лимиты по тарифу (Free / Pro / Business)
- Шифрование — токены провайдеров AES-256-GCM с конвертным шифрованием. Ключи централизованно на стороне RubikBot, у клиентов не хранятся.
- Журнал действий — каждое действие пишется в журнал для аудита (на тарифе Business)
Слой 3. Агентный цикл — сердце системы
Тут происходит главное. Три ключевых компонента:
Планировщик — один вызов модели со структурированным выводом:
{
"thoughts": "Пользователь просит исправить ошибку в auth.ts. Сначала нужно найти файл и понять контекст.",
"next_action": "call_skill",
"skill": "software-development/systematic-debugging",
"args": { "file": "lib/auth.ts" },
"expected_outcome": "локализация ошибки и предложение исправления"
}
Исполнитель — вызывает навык, ловит результат, прикрепляет к контексту следующей итерации.
Хранилище памяти — отдельная база SQLite на арендатора:
messages— все сообщения в текущей сессииmemories— долговременные факты (предпочтения пользователя, информация о проекте)skill_results_cache— кеш для идемпотентных вызовов
Главный цикл в псевдокоде:
while not done:
plan = call_planner(context, user_input, memory)
if plan.action == "respond":
return plan.message
result = execute(plan)
context += result
if max_steps_reached or stuck_detected:
break
Слой 4. Загрузчик навыков
87 встроенных навыков организованы по тематическим разделам:
research/(5) — arxiv, blogwatcher, polymarket, llm-wikicreative/(19) — от ascii-art до architecture-diagram, comfyui-image-genproductivity/(8) — google-workspace, linear, notion, airtable, maps, ocrgithub/(6) — code-review, PR-workflow, issuessoftware-development/(8) — plan, TDD, spike, systematic-debuggingmlops/(5) — huggingface-hub, vLLM, llama-cpp, dspysocial-media/(3),media/(4),autonomous-ai-agents/(3)
Каждый навык — это Python-модуль с манифестом manifest.yaml:
name: github/code-review
description: "Проверка GitHub PR..."
inputs:
pr_url: { type: string, required: true }
focus: { type: enum, values: [security, performance, style] }
outputs:
comments: { type: array }
summary: { type: string }
requires:
- env: GITHUB_PAT
- permissions: [read:pr, write:comment]
Загрузчик при старте сканирует директорию skills/, парсит манифесты, регистрирует в реестре инструментов, применяет разрешённый список по тарифу (Free — около 10 безопасных навыков, Pro — около 50, Business — все 87) и переопределения по арендатору (администратор может выключить навык для конкретного клиента).
Слой 5. Провайдеры моделей
Абстракция мульти-моделей через LiteLLM:
model: gpt-5→ OpenAI (через прокси для РФ)model: claude-4-6-opus→ Anthropicmodel: gemini-2-5-pro→ Googlemodel: yandexgpt→ Yandex Cloud- Маршрутизация с подменой (если OpenAI недоступен → Anthropic)
Все ключи провайдеров централизованно на стороне RubikBot — клиенту регистрироваться у OpenAI/Anthropic не нужно, биллинг идёт по тарифу в рублях.
Четыре ключевых архитектурных решения
Каждое решение в дизайне агента — это компромисс. Здесь — четыре главных решения Hermes с обоснованием и сравнением «как у других».
Решение 1. Один вызов планировщика vs нативный вызов инструментов
Отдельный вызов модели на решение каждого инструмента. Медленно, дорого, много галлюцинаций аргументов. На многошаговой задаче — 30+ вызовов модели, цена улетает.
Используем нативный tool_calls API провайдера если он поддерживается (OpenAI, Anthropic), откатываемся на структурированный вывод JSON для остальных (Yandex, GigaChat).
Цена решения: код сложнее (два пути обработки), но работает с любым провайдером — что критично для мульти-модельной платформы.
Решение 2. Трёхуровневая модель памяти
Самая важная архитектурная фишка для длинных сессий.
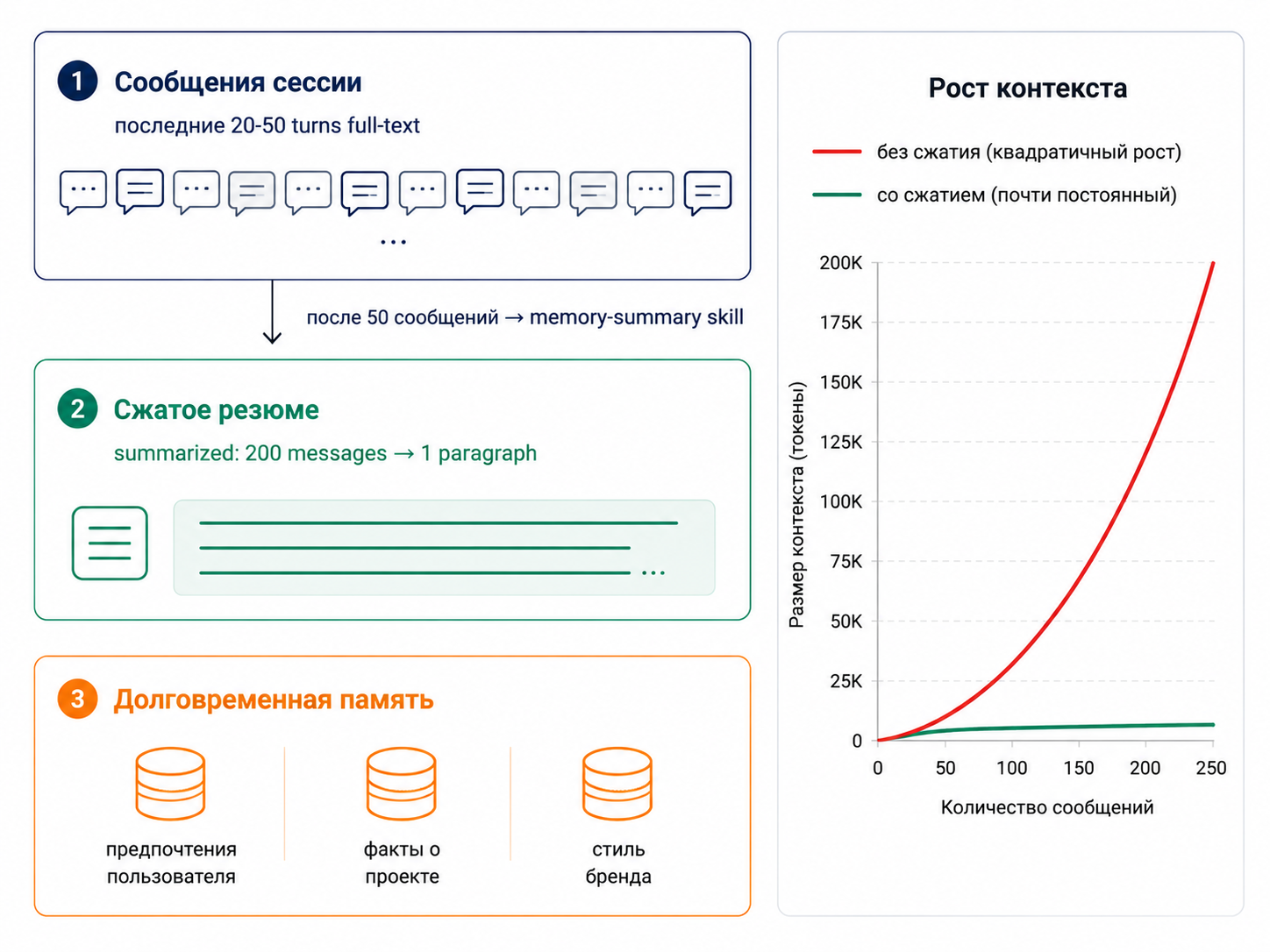
Три уровня:
- Сообщения сессии — последние 20–50 ходов полным текстом
- Сжатое резюме — старше 50 ходов сжимается в один абзац через навык
memory-summary - Долговременная память — отдельная таблица с фактами о клиенте (предпочтения, информация о проекте, стиль бренда) — не привязана к конкретной сессии
memory-summary запускается автоматически, когда контекст приближается к лимиту модели.
Цена решения: больше кода, но на длинных сессиях контекст не растёт квадратично. На сессии из 500 сообщений мы экономим примерно 80% токенов относительно «отправлять всё подряд».
Решение 3. Система навыков vs один большой промпт
Один большой системный промпт со всеми возможностями. Каждый запрос тратит токены на «инструкции», даже если используется только один навык.
Каждый навык — отдельный модуль со своим шаблоном промпта. Загрузчик подключает только активные. Системный промпт легче, навыки можно версионировать и публиковать через PR.
Плюсы:
- Экономия токенов (системный промпт не на 50 000 токенов)
- Версионирование навыков (v2 без влияния на остальные)
- Открытая контрибуция (любой может добавить навык через PR)
Минусы:
- Менее гладкая работа над задачами на стыке нескольких навыков
- Нужна явная композиция навыков для сложных сценариев
Решение 4. Условие остановки
Главная боль AutoGPT в 2023 — цикл «думаю-думаю-думаю» без видимого продвижения. Hermes решает гибридом:
max_iterations = 30 # жёсткий лимит итераций
stuck_detector_threshold = 3 # 3 шага без прогресса → стоп
if iterations >= max_iterations:
return "Достиг лимита 30 шагов, нужно вмешательство"
if stuck_counter >= stuck_detector_threshold:
return "Застрял на одном месте, последние 3 итерации без прогресса"
if action.tag == "destructive" and not user_approved:
return wait_for_user_approval()
Цена решения: иногда останавливается раньше времени на сложных задачах. Зато не зацикливается и не сжигает 500 ₽ токенов за один заход.
Мульти-арендность — изоляция и безопасность
Hermes работает в двух режимах: общем (на тарифах Free и Pro) и выделенном (на тарифе Business).
Общий режим (Free / Pro)
Один экземпляр Hermes обслуживает 100+ арендаторов. Изоляция на четырёх уровнях:
- Своя SQLite на каждого арендатора — кросс-арендаторные SQL-запросы технически невозможны
- Свой рабочий каталог
/data/tenant-{id}/ - Свои лимиты запросов в шлюзе
- Сетевая изоляция — каждый арендатор видит только свои учётные данные интеграций (Рубик-Блокнот, GitHub), зашифрованные при хранении
Модель угроз:
- Арендатор A не может прочитать данные арендатора B (через SQL-изоляцию)
- Инъекция промптов от арендатора A не может повлиять на B (отдельные процессы)
- Ошибка в навыке — максимум урон в текущем арендаторе (песочница)
Выделенный режим (Business)
Каждый арендатор получает выделенный экземпляр на нашей инфраструктуре — клиенту не нужно покупать или настраивать сервер. Под капотом:
- Свой PostgreSQL / SQLite
- Свой systemd-unit
- Своя Docker-сеть
- Свои переменные окружения (никогда не пересекаются с другими арендаторами)
Всё это управляется и обслуживается RubikBot. Клиент работает через UI и API, инфраструктурная часть закрыта.
Это нужно для:
- Соответствия 152-ФЗ (для финансовых, медицинских и государственных организаций)
- Изоляции данных на уровне процесса
- Поддержки собственных навыков (которые нельзя пускать в общий пул)
- Расширенных лимитов запросов
- Журнала действий для аудита
Если работаете с чувствительными данными или нужны собственные навыки — тариф Business это закрывает. Сервер, развёртывание, обновления, мониторинг — на нашей стороне. Никаких сторонних VPS, никаких отдельных подписок OpenAI.
Уроки полугода работы в проде
Все четыре урока — реальные провалы первой версии Hermes и их решения.
Урок 1. LLM галлюцинирует аргументы навыков
Проблема: модель ставит выдуманные значения для аргументов навыка. Например — придумывает ID страницы в Рубик-Блокноте, которой не существует.
Решение: валидация в загрузчике навыков. Если модель указала ID — мы проверяем существование до выполнения. Если нет — обратная связь в цикле: «недопустимый ID, доступные сейчас: [...]».
Урок 2. Сетевые вызовы падают непредсказуемо
Проблема: Рубик-Блокнот API превысил лимит, GitHub 500, OpenAI таймаут. В первой версии исключение всплывало вверх, сессия умирала.
Решение:
- Middleware повторных попыток с экспоненциальной задержкой
- Выводы навыков структурированы:
{ "error": "rate_limit", "retry_after": 60 } - Планировщик видит ошибку и решает: повторить / откатиться / сообщить пользователю
Урок 3. Стоимость токенов растёт нелинейно
Проблема: длинный агентный цикл = N шагов × полный контекст = O(N²) токенов. На сессии из 50 шагов это легко превращается в 5 000 ₽.
Решение:
- Навык
memory-summaryпосле 50 сообщений - Выводы навыков обрезаются до релевантной части (не весь файл)
- Лимит токенов на арендатора с уведомлением при приближении
Урок 4. Права доступа критичны
Проблема: один пользователь дал Hermes права write:all в GitHub и потом удивлялся, когда Hermes удалил PR «по ошибке».
Решение:
- Права по умолчанию — только чтение
- Каждый деструктивный навык — явное подтверждение пользователя
- Журнал действий для всех операций (для пост-мортема)
Сравнение с конкурентами
| Параметр | Hermes | Claude Code | OpenAI Swarm | AutoGPT |
|---|---|---|---|---|
| Провайдер моделей | Любой (мульти-LLM) | Только Anthropic | Только OpenAI | Многий (через обёртки) |
| Каталог навыков | 87 + свои | Встроенные инструменты | Ручное определение | Ручное + плагины |
| Память | Долговременная + сессия + сжатие | Только сессия | Только сессия | Долговременная (векторная) |
| Мульти-арендность | Да (в проде) | Нет (терминал) | Нет (библиотека) | Нет (терминал/веб) |
| Интерфейс | Telegram, MAX / веб / API / MCP | Только терминал | Библиотека | Терминал / веб |
| Открытый исходник | Ядро да, платформа нет | Нет | Да | Да |
| Зрелость в проде | В работе | В работе | Новый | Экспериментальный |
Дорожная карта до конца 2026 года
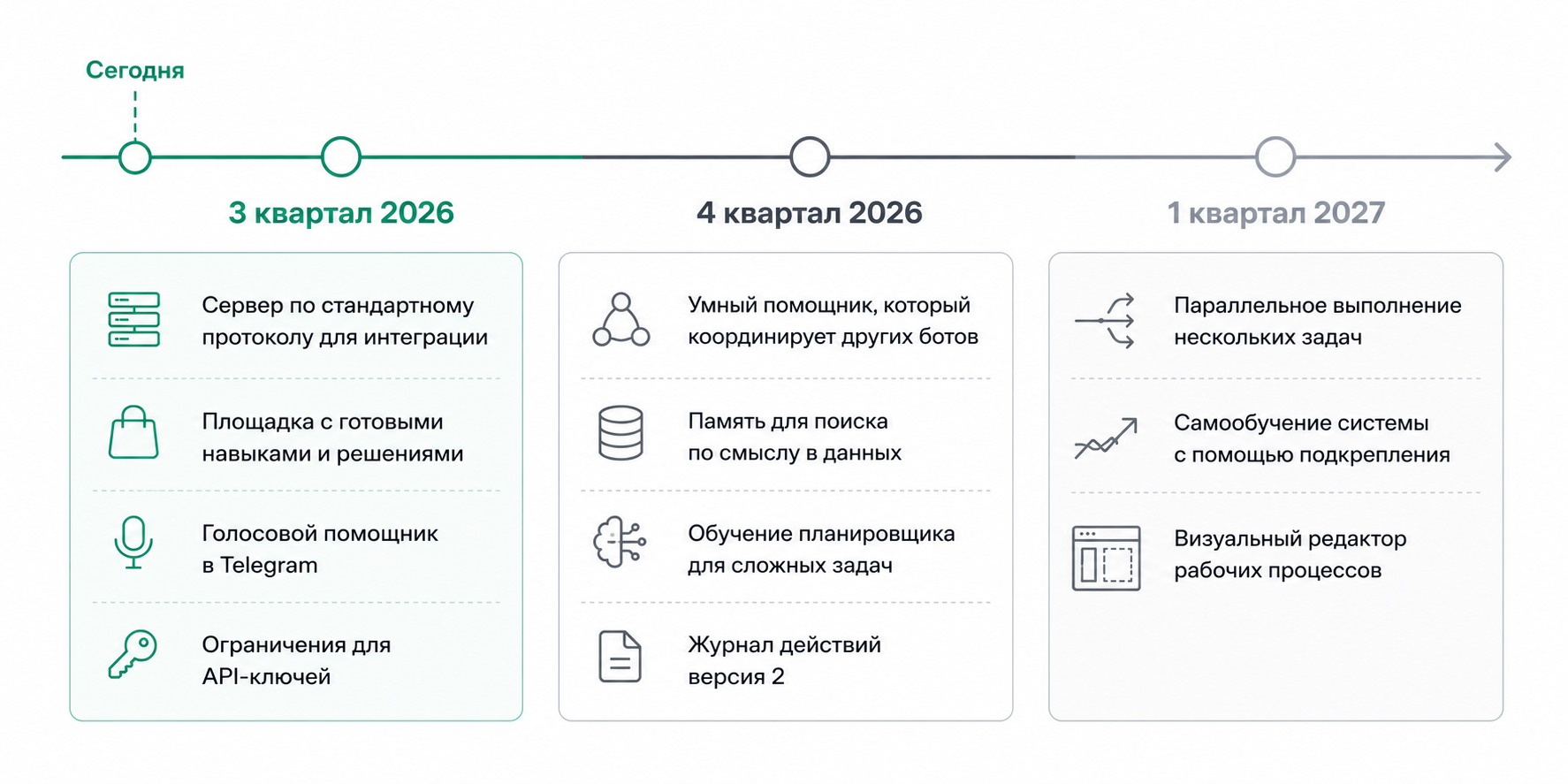
Q3 2026
- Нативный MCP-сервер — стандартный протокол для сторонних клиентов (Claude Desktop, Cursor)
- Маркетплейс навыков — публикация и продажа собственных навыков сообществом
- Голосовой интерфейс через голосовые сообщения Telegram, MAX
- Лимиты по API-ключам (по моделям, бюджету, IP)
Q4 2026
- Мульти-агент — один Hermes оркеструет других специализированных Hermes / специалистов
- Векторная память для семантического поиска в истории
- Дообучение планировщика на собственной модели для экономии стоимости
- Журнал действий версии 2 — детальные отчёты для compliance-аудитов
Q1 2027
- Параллельные ветви исполнения в одном цикле
- Self-improvement через обучение с подкреплением на собственных логах
- Визуальный редактор сценариев для не-программистов
Открытые проблемы — что ещё не решено
Честно о том, что остаётся головной болью даже в зрелой v2 архитектуре:
- Композиционное рассуждение. Задачи, требующие 10+ навыков последовательно, работают плохо. Модель «забывает» промежуточные шаги.
- Долгоиграющие задачи (более 30 минут). Нужна другая модель управления — текущий цикл не приспособлен.
- Оптимизация стоимости для высоких объёмов. На потоке в 1 миллион запросов в день экономика тонкая, каждый процент имеет значение.
Если вы исследователь и хотите помочь с одной из этих задач — напишите на research@rubikbot.com.
Что делать дальше
- Попробовать Hermes — /playground, бесплатно после регистрации (50 ₽ приветственного баланса хватает на 50–100 запросов)
- Прочитать сравнение с Claude Code — /blog/hermes-vs-claude-code, подробный поединок с итоговой таблицей выбора
- Кейсы команд, использующих Hermes — B2B SaaS, агентство, e-commerce
- Подключить к своему приложению — /signup, 50 ₽ приветственного баланса, активация Hermes за 30 секунд
Связанные материалы
Автор: Команда RubikBot