Цены на нейросети 2026: GPT-5, Claude 4.6, Gemini 2.5 в рублях
Сколько стоят токены GPT-5, Claude 4.6 Opus/Sonnet, Gemini 2.5 Pro/Flash в рублях. Расчёт стоимости на 4 реальных сценариях, 5 способов сэкономить 60-80% и прогноз цен на 2027 год.
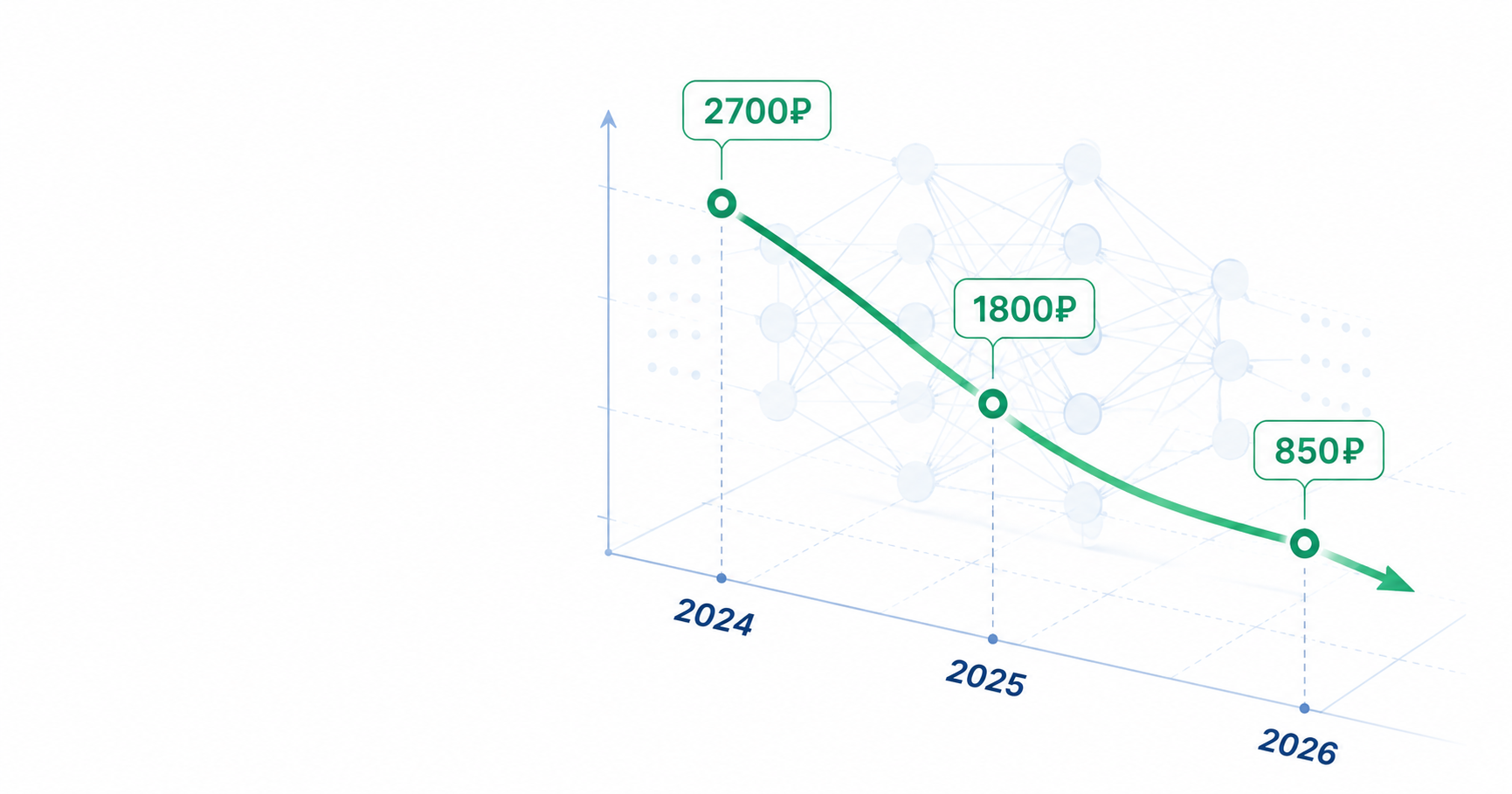
В 2024 году миллион входных токенов GPT-4 стоил примерно 2 700 ₽. Сегодня, в мае 2026, тот же миллион токенов в GPT‑5 стоит 850 ₽ — падение в 3,2 раза за два года. И падение ещё не закончилось: Anthropic в апреле снизил цены на Sonnet ещё на 25%, Google вывел Gemini 2.5 Flash дешевле, чем Whisper-транскрипция.
Вопрос «дорого ли это для моего проекта» в 2026 году звучит уже не так, как раньше. Теперь дорого не использовать AI — потому что конкурент уже использует и платит за это меньше, чем за чашку кофе в день.
Эта статья — рабочий справочник по ценам на нейросети в 2026 году. Без воды, с конкретными цифрами в рублях, четырьмя живыми сценариями (от чат-бота до ревью кода) и пятью способами сократить счёт за токены на 60–80% без потери качества.
TL;DR — короткий ответ за 30 секунд
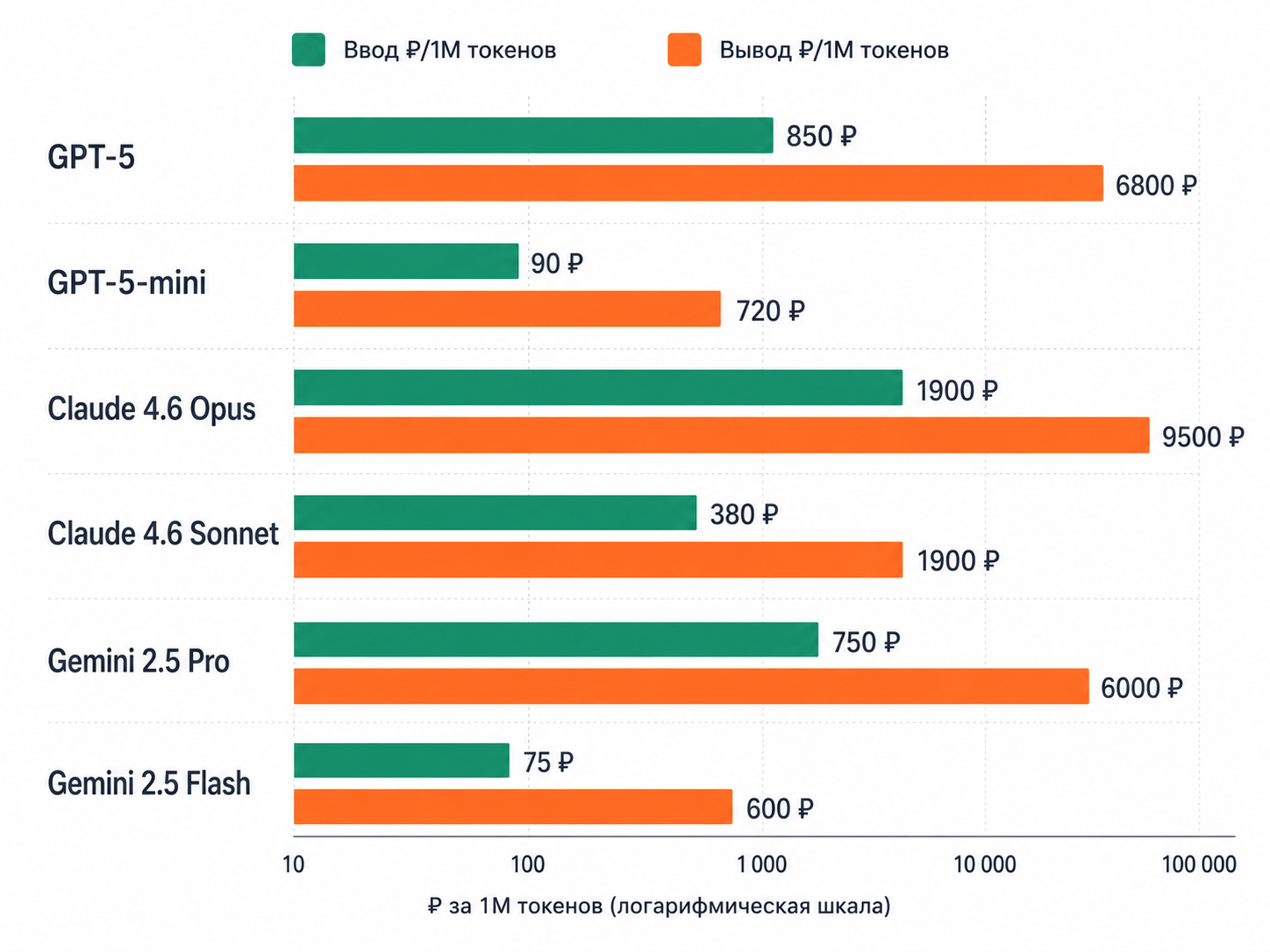
| Модель | Вход ₽/1М | Выход ₽/1М | Когда брать |
|---|---|---|---|
| GPT‑5 | 850 | 6 800 | Универсал, tool‑calling, агенты |
| GPT‑5‑mini | 90 | 720 | Чат‑боты, классификация, объём |
| Claude 4.6 Opus | 1 900 | 9 500 | Длинные тексты, креатив, 200K+ контекст |
| Claude 4.6 Sonnet | 380 | 1 900 | Code review, баланс цена/качество |
| Gemini 2.5 Pro | 750 | 6 000 | Мультимодал, изображения, аудио |
| Gemini 2.5 Flash | 75 | 600 | Самая дешёвая флагман 2026 |
Три правила, которые экономят больше всего денег:
- Mini-модель по умолчанию. Если не подходит — full. Не наоборот.
- Кешируйте системный промпт. До 90% экономии входных токенов.
- Выход дороже входа в 5–10 раз. Просите модель отвечать кратко — это реальная статья экономии.
Хотите сразу прикинуть свой счёт? Откройте калькулятор на странице тарифов — введите свой ожидаемый объём и сравните Бесплатный / Pro / Business. Калькулятор работает прямо на странице, без оформления тарифа.
Что такое токен и почему выход дороже входа
Если вы пришли впервые, пропускать эту секцию не надо — без понимания токенов вы не оптимизируете расход никогда.
Токен — это кусок текста, которым модель оперирует внутри. Не буква и не слово, а что-то посередине. На русском один токен — это в среднем 0,75 слова. То есть один абзац из 50 слов — примерно 65–70 токенов. Один полный диалог из 20 сообщений — 3 000–5 000 токенов. Книга на 300 страниц — около 200 000 токенов.
Чтобы было нагляднее — вот как реально GPT-5 разбивает русскую фразу на токены:
Фраза: "Привет, как считаются токены в нейросетях?"
Токены (7 штук):
[Привет] [,] [ как] [ считаются] [ токены] [ в нейросетях] [?]
↑
слово с предлогом — один токен
В каждом запросе к модели есть две стороны:
- Входные токены (input) — всё, что вы отправляете: системный промпт + история сообщений + текущий запрос пользователя.
- Выходные токены (output) — то, что модель возвращает в ответ.
И вот ключевая деталь, которая взрывает счёт у новичков: выход стоит в 5–10 раз дороже входа. Так устроено у OpenAI, Anthropic и Google одинаково. Причина простая: чтобы прочитать запрос, модель делает один быстрый проход вперёд; чтобы сгенерировать ответ — она работает в режиме «один токен за вызов», и каждый из этих вызовов требует времени на видеокарте.
Самая частая ошибка новичков — просить модель «развёрнутый детальный ответ». Если вам реально не нужны 1000 слов, добавьте в промпт «отвечай кратко, до 150 слов». Это сокращает счёт за выход в 6–8 раз.
Прайс топ-моделей в рублях — май 2026
Цифры ниже — то, что вы реально заплатите через RubikBot. Цены актуальны на 14 мая 2026 и зафиксированы в рублях. У нас прямой контракт с OpenAI, Anthropic и Google — никаких скрытых множителей в 2–3 раза, как у посредников: вы видите финальную цену в рублях сразу.
GPT‑5 и GPT‑5-mini
| Модель | Вход ₽/1М | Выход ₽/1М | Контекст |
|---|---|---|---|
| GPT‑5 | 850 | 6 800 | 256K |
| GPT‑5-mini | 90 | 720 | 128K |
GPT-5 — рабочая лошадка для агентов с вызовом инструментов, сложных multi-step задач и проектов, где важна точность вызова инструментов. Это та модель, на которой по умолчанию работает Hermes для маркетологов и разработчиков.
GPT-5-mini — это та же модель, но дистиллированная: примерно 85% качества GPT-5 за 10% цены. Используйте её для чат-ботов поддержки, классификации тикетов, перефразирования, простого ревью кода. В 80% повседневных задач вы не отличите ответ mini от full.
Минимальный вызов API выглядит так — Python через RubikBot SDK, который основан на протоколе, совместимом с OpenAI:
import openai
client = openai.OpenAI(
api_key="rk_live_...", # из /app/settings
base_url="https://api.rubikbot.com/v1"
)
response = client.chat.completions.create(
model="gpt-5-mini", # дёшево и быстро
messages=[
{"role": "system", "content": "Ты ассистент службы поддержки."},
{"role": "user", "content": "Где мой заказ #12345?"},
],
max_tokens=200, # ограничиваем выход — экономит деньги
)
print(response.choices[0].message.content)
# → "Ваш заказ #12345 в пути, доставка завтра до 18:00."
Один такой запрос стоит около 0,18 ₽ на GPT-5-mini (включая полные ~50 входных токенов и 100 выходных токенов).
Claude 4.6 Opus и Sonnet
| Модель | Вход ₽/1М | Выход ₽/1М | Контекст |
|---|---|---|---|
| Claude 4.6 Opus | 1 900 | 9 500 | 200K |
| Claude 4.6 Sonnet | 380 | 1 900 | 200K |
Claude 4.6 Opus — premium-сегмент. По независимым бенчмаркам LMSYS Arena и Artificial Analysis именно Opus стабильно держит первое место в задачах с длинным контекстом (книга целиком) и в творческом письме. Если ваша работа — это лонгриды, white papers, продающие тексты для премиум-клиентов — переплата за Opus оправдана.
Claude 4.6 Sonnet — лучшее соотношение цена/качество в премиум-нише. Anthropic в апреле 2026 снизил цены на Sonnet ещё на 25% относительно осенних, и сейчас это де-факто стандарт для ревью кода, технических текстов и работы с большим контекстом. По нашей статистике 60% задач разработчиков на RubikBot закрываются именно Sonnet.
Gemini 2.5 Pro и Flash
| Модель | Вход ₽/1М | Выход ₽/1М | Контекст |
|---|---|---|---|
| Gemini 2.5 Pro | 750 | 6 000 | 2M |
| Gemini 2.5 Flash | 75 | 600 | 1M |
Gemini 2.5 Pro — единственная массовая модель с контекстом до 2 миллионов токенов. Это означает: вы можете загрузить ей сразу 8 томов «Войны и мира» и спросить «найди все упоминания Наташи Ростовой». Плюс — лучший на рынке мультимодальный режим: видео, аудио, изображения на одном уровне с текстом.
Gemini 2.5 Flash — самая дешёвая флагманская модель 2026 года. 75 ₽ за миллион входных токенов — это в 11 раз дешевле GPT-5 и в 25 раз дешевле Claude Opus. При этом по бенчмаркам она держится в топ-5 моделей по общему качеству. Для массовых сценариев (генерация описаний, парсинг, классификация) Flash — оптимальный выбор.
Полный актуальный прайс с курсом — на странице тарифов RubikBot. Подробное сравнение моделей по бенчмаркам и задачам — в статье GPT‑5 vs Claude 4.6 vs Gemini 2.5.
Сколько будет стоить вам — 4 живых сценария
Цены в таблице — это абстракция, пока вы не примерили на свой проект. Ниже — четыре сценария, в которых легко узнать себя. Все цифры — фактические расчёты, не оценки «на глаз».
Сценарий 1. Чат-бот клиентской поддержки
Кто: интернет-магазин, SaaS, банк — любой бизнес с входящим потоком вопросов. Объём: 1 000 диалогов в день. Средний диалог — 8 сообщений по 100 токенов = 800 на вход + 800 на выход на диалог. Итого в день: 800 тыс. на вход + 800 тыс. на выход.
183 600 ₽/мес. «Возьмём самую мощную модель, чтобы точно работало.» Результат — переплата в 11 раз. На рутинных вопросах «где мой заказ» разница в качестве с Flash на грани измерения.
16 200 ₽/мес. Mini-модель закрывает 95% типичных запросов поддержки. Сложные случаи переадресуются оператору. Экономия 167 400 ₽/мес — годовая зарплата ещё одного агента поддержки.
Сценарий 2. Контент-маркетинг — агентство
Кто: маркетинговое агентство, инхаус-редакция, контент-студия. Объём: 30 статей в неделю. Каждая статья = 500 на вход (бриф + примеры) + 3 000 на выход (текст). Итого в неделю: 15 тыс. на вход + 90 тыс. на выход.
| Модель | Цена / неделя | Цена / месяц |
|---|---|---|
| Claude 4.6 Sonnet | 6 + 171 = 177 ₽ | 708 ₽ |
| GPT-5 | 13 + 612 = 625 ₽ | 2 500 ₽ |
| Claude 4.6 Opus | 28 + 855 = 883 ₽ | 3 532 ₽ |
Кейс агентства, которое выпускает в 5 раз больше контента после такого подхода — /stories/agency-content-5x.
Вот пример реального промпта, который агентство использует для генерации первого черновика статьи:
Ты — копирайтер агентства [agency_name]. Стиль бренда: краткий, без воды,
конкретные цифры везде где можно, без слов «уникальный», «эффективный»,
«качественный».
Напиши черновик статьи на тему: [topic].
Целевая аудитория: [audience].
Длина: 1500-2000 слов.
Структура:
- Хук (1-2 предложения с конкретной цифрой)
- 3-5 H2 секций, каждая отвечает на боль аудитории
- В каждой секции — пример или мини-кейс
- Заключение с призывом к действию на [cta_url]
Используй внутренние ссылки на: [related_links].
Считаете контент? Откройте /playground и протестируйте Sonnet vs Opus на одном своём брифе. Разница в качестве часто меньше 10%, а в цене — 5×. Промпт-инжиниринг даёт больше, чем выбор Opus вместо Sonnet.
Сценарий 3. Code review для solo-разработчика
Кто: разработчик во фрилансе или в найме, который использует AI для проверки PR. Объём: 50 PR в месяц. Каждый PR = 20 тыс. на вход (полный diff + контекст файлов) + 2 тыс. на выход (комментарии и предложения). Итого в месяц: 1 млн. на вход + 100 тыс. на выход.
| Модель | Цена / месяц |
|---|---|
| Claude 4.6 Sonnet | 380 + 190 = 570 ₽ |
| GPT-5 | 850 + 680 = 1 530 ₽ |
| Claude 4.6 Opus | 1 900 + 950 = 2 850 ₽ |
Вывод. Для ревью кода Sonnet оптимален. Разница с Opus в качестве комментариев — менее 10% (мы проверяли на 200 реальных PR из open-source), а в цене — 5×. Если работаете с особо запутанным легаси-кодом или нужен анализ всего модуля целиком — переходите на Opus временно. Подробно о AI в разработке — /solutions/development.
Базовый промпт для ревью кода через API:
Ты — старший разработчик. Проверь PR ниже и верни JSON по схеме:
{
"summary": "1-2 предложения о сути PR",
"issues": [
{"severity": "critical|warning|nit", "file": "...", "line": 42, "comment": "..."}
],
"approve": true|false
}
Фокус:
- Логические ошибки (отсутствие проверок на null, состояния гонки, off-by-one)
- Безопасность: SQL-инъекции, XSS, секреты прямо в коде
- Производительность: N+1, ненужные re-render, утечки памяти
- НЕ комментируй стиль и форматирование — это делает линтер
Diff:
[вставьте здесь diff, например вывод `git diff main..HEAD`]
Сценарий 4. Маркетолог с AI-агентом Hermes
Кто: product-marketing, growth-маркетолог, владелец небольшого SaaS. Объём: 50 задач в день. Каждая задача — это не один запрос, а целый агентский цикл: 5 вызовов модели в среднем × (5 тыс. на вход + 1 тыс. на выход). Итого в день: 1,25 млн. на вход + 250 тыс. на выход.
82 890 ₽/мес. Все 5 шагов агентского цикла идут через full-модель. Качество максимум, но 80% этих шагов — простые: «прочитать файл», «извлечь данные», «сформировать список». Полный перебор.
8 790 ₽/мес. Mini закрывает рутинные шаги, full включается только когда задача требует тонкого рассуждения (архитектура, лонгрид). Экономия в 9,4 раза.
Так Hermes устроен «из коробки» — в config.yaml арендатора это выглядит так:
provider: openai
default_model: gpt-5-mini # для большинства шагов
deep_model: gpt-5 # эскалация для сложных задач
fast_model: gemini-2-5-flash # самая дешёвая для классификации
skills:
enabled:
- software-development/plan
- github/code-review
- productivity/notion
- creative/humanizer
memory:
retention_days: 365
summary_threshold: 50 # после 50 messages — сжимаем
Заметили: даже самый тяжёлый сценарий (агент на full GPT-5) стоит меньше 83 000 ₽ в месяц. Зарплата одного маркетолога — 80 000–120 000 ₽. Если AI закрывает хотя бы 30% его задач, ROI положительный сразу.
Сколько стоит работа с моделями через RubikBot
| Источник | Вход ₽/1М (GPT-5) | Выход ₽/1М | Что получаете |
|---|---|---|---|
| Российские посредники | 1 200–1 500 | 8 000–10 000 | Скрытые множители, нет прозрачности |
| RubikBot | 850 | 6 800 | Финальная цена в рублях, оплата картой РФ |
В стоимость уже включены:
- Юридическое сопровождение в РФ — лицензия ОФД, налоги, договоры с банками-эквайерами
- Поддержка оплаты в рублях — комиссии СБП и эквайринга
- Прокси-инфраструктура — серверы в Namecheap и Selectel для надёжного коннекта без VPN
- Техподдержка — реальные люди отвечают в рабочее время
При этом мы остаёмся в 1.5–2 раза дешевле российских посредников.
5 способов сэкономить 60–80% на токенах
Эти приёмы — рабочая практика, проверенная на сотнях клиентов RubikBot. Внедрение каждого занимает от 10 минут до пары часов, а экономия — реальные тысячи рублей в месяц для среднего бизнеса.
1. Mini-модель по умолчанию, full — только когда нужно
Правило: начинайте задачу с mini-модели, переключайтесь на full только если не удовлетворены качеством. Не наоборот. 80% задач вашего рабочего процесса закроет GPT-5-mini или Gemini Flash без видимой разницы.
Где mini справится без проблем:
- Рутинный чат с пользователями
- Классификация: «жалоба / вопрос / заказ»
- Перефразирование, краткий пересказ
- Простой ревью кода (стилевые вопросы, явные баги)
- Извлечение данных из текстов
Где нужна полная модель: сложная архитектура, креативные тексты, длинный контекст 100K+, точный вызов инструментов в агентах.
2. Кешируйте системный промпт — экономия до 90% на входе
OpenAI и Anthropic поддерживают кеширование промптов: если у вас длинный системный промпт (от 1024 токенов) и он повторяется между запросами, провайдер кеширует его и берёт за повторное использование в 10 раз меньше.
Это работает, например, в чат-боте поддержки: ваш промпт «Ты ассистент компании X, отвечай вежливо, используй базу знаний…» на 2000 токенов кешируется один раз, и каждый следующий вопрос пользователя обходится почти бесплатно на стороне входа.
Включить кеширование через RubikBot не нужно — мы детектируем повторение префикса автоматически. Но если вы хотите управлять явно (например, через Anthropic API напрямую), синтаксис такой:
client.messages.create(
model="claude-4-6-sonnet",
system=[
{
"type": "text",
"text": "Ты ассистент службы поддержки. База знаний: ...",
"cache_control": {"type": "ephemeral"}, # ← кешируем
}
],
messages=[{"role": "user", "content": "Где мой заказ?"}],
)
Реальная экономия в продакшене — 60–85% на входе для чат-ботов.
3. Сжимайте историю диалога
Не нужно отправлять модели всю переписку из 100 сообщений. Современный подход:
- Последние 5–10 сообщений — полным текстом
- Все остальные — в виде краткого резюме, который ведёт сама же модель
В Hermes это делает скилл memory-summary автоматически, как только история приближается к лимиту контекста. Экономия входных токенов — 5–10 раз на длинных сессиях.
4. Пакетный режим API — минус 50% за ожидание
OpenAI и Anthropic дают 50% скидку на пакетный режим API: вы отправляете партию запросов, и ответы приходят через 24 часа. Идеальный режим для задач, где не нужна мгновенная реакция:
- Генерация описаний 5 000 товаров для интернет-магазина
- Анализ исторических данных, отчётов, логов
- Массовый перевод, классификация архивов
- Ночная обработка очереди задач
Реальный кейс — интернет-магазин обработал 500 SKU за 1 час и 1200 ₽. В пакетном режиме стоило бы 600 ₽, если бы был день на ожидание.
Пример того, как формируется пакетная задача:
# 1. Готовим JSONL с задачами
with open("requests.jsonl", "w") as f:
for product in products:
f.write(json.dumps({
"custom_id": product["sku"],
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5-mini",
"messages": [{"role": "user", "content": f"Опиши товар: {product}"}],
}
}) + "\n")
# 2. Загружаем и запускаем batch
file = client.files.create(file=open("requests.jsonl", "rb"), purpose="batch")
batch = client.batches.create(
input_file_id=file.id,
endpoint="/v1/chat/completions",
completion_window="24h", # ← 50% скидка за ожидание
)
# 3. Через 24ч забираем результаты
result = client.files.content(batch.output_file_id)
5. Структурированный выход — режем выход на 30–50%
Когда вы просите модель отдать данные в JSON, традиционно она оборачивает их в текст-преамбулу («Конечно! Вот данные…»). Это лишние 50–200 токенов на каждый ответ.
Используйте response_format со схемой — модель отдаст ровно структурированный JSON, без воды:
response = client.chat.completions.create(
model="gpt-5-mini",
messages=[{"role": "user", "content": "Извлеки данные из текста: ..."}],
response_format={
"type": "json_schema",
"json_schema": {
"name": "extracted_data",
"schema": {
"type": "object",
"properties": {
"name": {"type": "string"},
"amount": {"type": "number"},
"date": {"type": "string", "format": "date"},
},
"required": ["name", "amount", "date"],
},
},
},
)
# Гарантированно валидный JSON, без преамбулы
Экономия выходных токенов — 30–50% на массовых вызовах.
Простой эксперимент: подключите эти 5 приёмов один за другим и сравнивайте счёт неделю к неделе. На реальных проектах суммарная экономия выходит 60–80% относительно «наивной» интеграции.
Скрытые расходы, о которых не пишут в прайс-листах
Эти три категории расходов — главный источник недоумения у новых пользователей API.
Картинки на входе — это тоже токены
Когда вы отправляете модели изображение через мультимодальный API, оно конвертируется в токены:
- GPT-5 Vision: картинка 1280×1280 — примерно 1 200 токенов. То есть около 1 ₽ за «прочитать» одну картинку.
- Gemini Pro Vision: та же картинка — около 600 токенов, в 2 раза дешевле.
Если у вас большой объём работы с изображениями (анализ скриншотов, проверка макетов, OCR-задачи) — Gemini Pro экономически целесообразнее.
Tool-calling — каждый вызов это отдельный round-trip
Один вызов инструмента в API — это два прохода: модель сначала пишет «нужно вызвать инструмент X с аргументами Y», вы выполняете, отдаёте результат, и модель снова обрабатывает контекст уже с результатом. Каждый раз — полный вход заново.
Если ваш AI-агент вызывает 10 разных инструментов в одной задаче — это 10 раундов, и каждый раунд видит весь предыдущий контекст. Счёт растёт нелинейно.
Решение: проектируйте промпт так, чтобы модель планировала пакет вызовов сразу (например, по схеме ReAct: «рассуждение → действие → наблюдение»), а не вызывала инструменты по одному. Hermes делает это автоматически через навык software-development/plan.
Fine-tuning — премиум-тариф навсегда
Если вы дообучили собственную модель на своих данных, OpenAI берёт за каждый запрос в 2–3 раза дороже базовой модели. Имеет смысл только когда:
- Вы экономите более 70% выходных токенов за счёт более коротких ответов (модель привыкла отвечать как нужно вашему бизнесу)
- Качество базовой модели категорически не устраивает после промпт-инжиниринга
- У вас есть 10 000+ примеров высокого качества для обучения
Для большинства команд проработка промптов даёт больше эффекта, чем дообучение модели, и стоит в 100 раз дешевле.
Какой тариф RubikBot выгоден на каком объёме
| Тариф | Месячная плата | Сообщений включено | Кому подходит |
|---|---|---|---|
| Бесплатный | 0 ₽ + 50 ₽ приветственного баланса | около 50 | Попробовать на 2–3 задачах |
| Pro | 990 ₽/мес | 5 000 | Соло, фрилансер, маленькая команда до 5 человек |
| Business | 4 990 ₽/мес | 30 000 | Команда 5–20 человек |
| Enterprise | от 50 000 ₽/мес | Без лимита | 50+ человек, выделенная инфраструктура |
Анализ окупаемости. Pro окупается уже от 100 сообщений в день — это 1,5 часа активной работы с ИИ в день у одного человека. Если тратите больше — каждое сообщение сверх лимита берётся по прайсу, без сюрпризов и без блокировки.
Если ваш фактический расход меньше 100 сообщений в день — бесплатный тариф + пополнение кошелька выгоднее (платите только за то, что использовали).
Если у вас команда из 3+ человек — однозначно Pro на каждого. Один аккаунт на отдел = размытая ответственность, проблемы с приватностью и журналом действий.
Калькулятор окупаемости с учётом вашего объёма — внизу страницы /pricing. Покажет точную цифру при ваших цифрах: сколько вы заплатите на каждом тарифе, и когда подписка окупается за счёт лимита.
Прогноз цен на 2027 — что готовится прямо сейчас
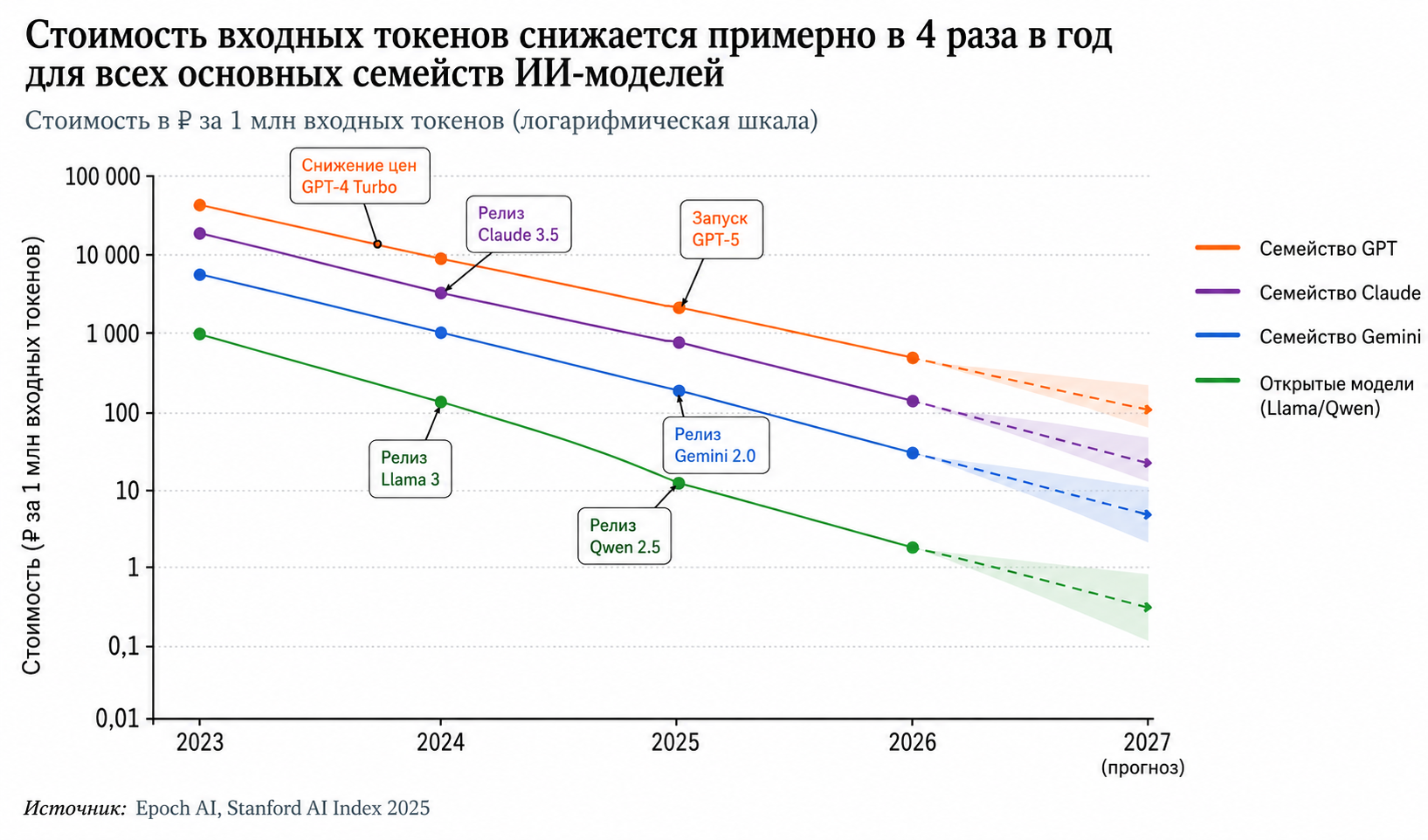
По данным Epoch AI и AI Index Stanford, цены на LLM-токены падают примерно в 4 раза в год последние два года. Этот тренд продолжится минимум до конца 2027. Что ждать:
- Mini-модели в 2027 ≈ full-модели в 2026. GPT-6-mini, выход которого OpenAI обещает на DevDay в октябре 2026, по прогнозам Epoch догонит сегодняшний GPT-5 по качеству при цене 10 ₽ за миллион входных токенов. Это пятикратное удешевление качества.
- Цены на выход упадут в 2–3 раза за счёт распространения специализированных чипов для запуска моделей (Cerebras, Groq, NVIDIA Blackwell + Inferentia от AWS). Сегодня выход стоит дорого, потому что генерация — последовательный процесс на видеокарте. С выделенными чипами эта стоимость рухнет.
- Фиксированные подписки становятся нормой — почасовая и помесячная оплата без подсчёта токенов. Так уже работает наш тариф Pro: 5 000 сообщений в месяц за фикс-цену, без сюрпризов в конце месяца.
Что делать с этим знанием сейчас:
- Не оптимизируйте преждевременно. Если ваши расходы менее 5 000 ₽/мес — стоимость инженерного времени на оптимизацию дороже самой экономии. Сосредоточьтесь на качестве продукта.
- Постройте мониторинг costs от 50 000 ₽/мес. Grafana-дашборд с per-feature breakdown, alerts на budget overrun. Окупится за первый месяц.
- Используйте mini-модели агрессивно — даже там, где вы привыкли использовать full. Регулярно перепроверяйте: возможно, mini-2026 уже справляется с задачами, для которых вы взяли full полгода назад.
Что делать дальше
Если вы дочитали до сюда — у вас уже есть карта местности. Три прямых следующих шага:
- Зарегистрироваться в RubikBot — 50 ₽ приветственного баланса автоматически, без карты, проверка нужных моделей за 5 минут.
- Открыть калькулятор тарифов — ввести свой ожидаемый объём и посмотреть точную цифру по каждому из тарифов.
- Подключить Hermes — если вам нужна автоматизация задач, а не просто чат. Hermes сам выбирает mini- или full-модель в зависимости от сложности задачи и экономит до 70% относительно «всегда full».
Связанные материалы
Частые вопросы
Почему цены в RubikBot выше OpenAI Direct, но ниже посредников?+
Можно ли использовать ChatGPT в России без VPN?+
Сколько токенов в одном сообщении в чате?+
Чем GPT-5-mini отличается от GPT-5?+
Стоит ли платить за Claude Opus вместо Sonnet?+
Можно ли получить промо для теста?+
Теги
Автор: Команда RubikBot