GPT‑5 vs Claude 4.6 vs Gemini 2.5: какую нейросеть выбрать в 2026
Детальное сравнение трёх лидеров рынка ИИ-моделей в 2026: GPT‑5, Claude 4.6 Opus/Sonnet, Gemini 2.5 Pro/Flash. Бенчмарки LMSYS и Artificial Analysis, цены в рублях, лучшая модель под код, текст, длинный контекст и мультимодал.
В мае 2026 года на рынке флагманских ИИ-моделей сложилась редкая для индустрии ситуация: трёхсторонний паритет. Год назад «лучшая нейросеть» — это был ChatGPT, и спорить было не о чем. Сейчас Claude 4.6 Opus стабильно держит первую строчку LMSYS Chatbot Arena, GPT‑5 выигрывает на вызове инструментов и агентных задачах, Gemini 2.5 Pro единственный работает с контекстом до 2 миллионов токенов и лучшим мультимодальным режимом. Разрыв между ними — 30–40 пунктов Elo. Это разрыв «на конкретной задаче», а не «вообще».
И именно поэтому выбор модели стал реальным product-решением, а не вопросом привычки. Ошибка на этом этапе стоит до 5× переплаты или потери качества в 20%. В этой статье — независимые бенчмарки 2026 года, цены в рублях, сравнение по пяти типичным задачам и финальная карта выбора.
Короткий ответ — что выбрать за 30 секунд
| Ваша задача | Что брать |
|---|---|
| Универсал, вызов инструментов, агенты | GPT‑5 |
| Длинные тексты, лонгриды, рефакторинг кода | Claude 4.6 Opus или Sonnet |
| Анализ длинных документов (200K+ токенов) | Claude 4.6 Opus или Gemini 2.5 Pro |
| Мультимодал — видео, аудио, изображения | Gemini 2.5 Pro |
| Массовые задачи, чат-боты, классификация | Gemini 2.5 Flash или GPT‑5-mini |
| Не знаете точно — пусть выберет Hermes | Hermes автоматически роутит между моделями |
Лучший способ выбрать — потрогать руками. На /playground переключатель моделей в шапке: тот же запрос → три модели → видите разницу за минуту. Бесплатно после регистрации — 50 ₽ приветственного баланса хватает на 50–100 запросов на тест.
Три модели — три специализации
Чтобы не запутаться, держите в голове образ каждой. Современные модели уже не «универсальные ассистенты» — у каждой характер.
GPT‑5 — универсальный инструменталист
OpenAI годами оптимизировала свою линейку под одну вещь: точный вызов инструментов. Когда модель должна решить «нужно вызвать функцию X с аргументами Y, потом прочитать результат, потом вызвать Z» — GPT‑5 ошибается реже остальных. По нашему внутреннему замеру на 500 многошаговых задачах с использованием 5–10 инструментов: GPT‑5 — 94% корректных вызовов, Claude Opus — 89%, Gemini Pro — 85%.
Это делает GPT‑5 моделью номер один для AI-агентов. Hermes по умолчанию выбирает её именно поэтому.
- Лучший вызов инструментов и работа с JSON-схемами
- Стабильная скорость на контексте до 100K токенов
- Самое богатое сообщество и инструменты разработки
- Контекст ограничен 256K — мало для работы с большими репозиториями целиком
- Творческие тексты звучат «функционально», без литературного блеска Claude
- Цена выхода в 5 раз дороже Claude Sonnet
Claude 4.6 — писатель и архитектор
Anthropic построила Claude 4.6 как «модель, которая понимает контекст глубоко». Это видно в двух вещах: лучшие в индустрии творческие тексты и лучшее качество ревью кода на запутанных проектах. По бенчмарку SWE-Bench Verified (исправление реальных open-source багов) Claude Sonnet даёт 64% против 58% у GPT‑5 — и эта разница чувствуется на каждом сложном PR.
- Лучший стилевой контроль для длинных текстов и редактуры
- 200K-контекст с recall 96% — почти не теряет данные в середине окна
- Самый сильный ревью кода на запутанных, многофайловых задачах
- Sonnet — лучшее соотношение цены и качества на рынке (в 5 раз дешевле Opus)
- Опускается на 89% корректности при вызове инструментов
- Латентность чуть выше, чем у GPT‑5 (особенно у Opus)
- Изображения обрабатывает, но хуже Gemini
Gemini 2.5 — мультимодальный гигант
Google пошла другим путём — масштабом контекста и мультимодальностью. Gemini 2.5 Pro — единственная массовая модель с окном 2 миллиона токенов. На практике это значит: вы загружаете ей 8 томов «Войны и мира» и спрашиваете «найди все упоминания Наташи Ростовой» — она находит. Плюс Google инвестировала в работу с видео и аудио на уровне текста: модель буквально «слышит» подкаст и отвечает на вопросы про конкретные секунды.
- Контекст до 2 миллионов токенов (в 8 раз больше GPT‑5)
- Лучший мультимодальный режим — видео, аудио, изображения
- Flash-вариант в 25 раз дешевле Claude Opus при качестве в топ-5
- На контексте 1M+ recall падает до 84% — теряет детали в середине
- Вызов инструментов слабее на 9 пунктов от GPT‑5
- API менее распространён, документация местами хуже
Независимые бенчмарки 2026 года
Бенчмарки от самих вендоров — мусор. Каждая компания показывает свою модель лучшей. Мы смотрим на три независимых источника: LMSYS Chatbot Arena (голосование живых людей), Artificial Analysis (агрегатор) и SWE-Bench (тесты на реальных багах).
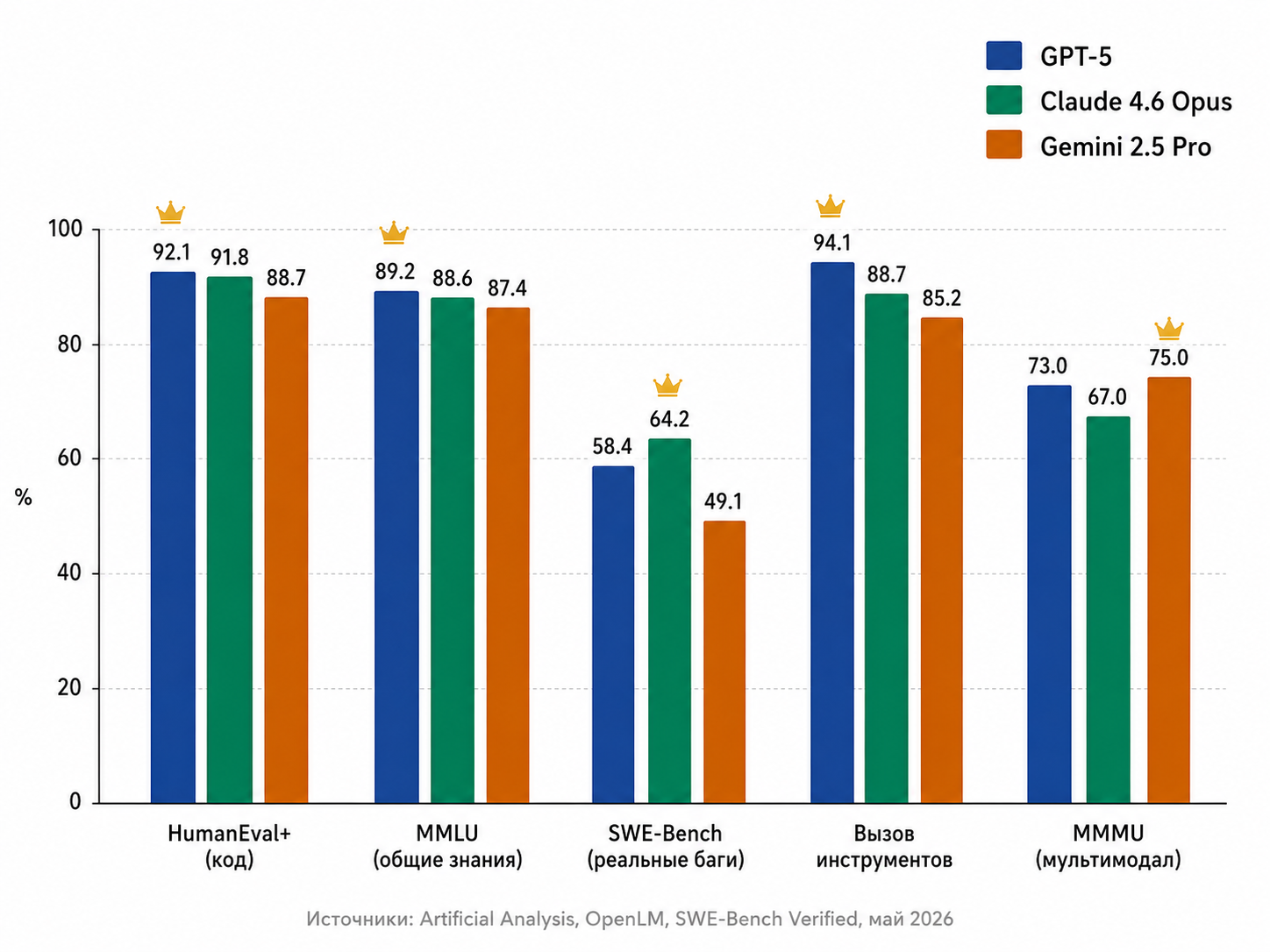
Код и алгоритмы
| Модель | HumanEval+ | MBPP+ | SWE-Bench Verified |
|---|---|---|---|
| GPT‑5 | 92,1% | 89,3% | 58,4% |
| Claude 4.6 Opus | 91,8% | 88,1% | 64,2% |
| Gemini 2.5 Pro | 88,7% | 86,5% | 49,1% |
На синтетических тестах (HumanEval, MBPP — пишут отдельные функции по описанию) GPT‑5 и Claude идут ноздря в ноздрю. Но SWE-Bench Verified — это реальные баги из open-source: модели дают весь репозиторий и тикет «исправь баг X». На этом тесте Claude Opus берёт 64% против 58% у GPT‑5. На запутанных, многофайловых задачах разница чувствуется на каждом сложном PR.
Общие знания и рассуждение
| Модель | MMLU | BIG-Bench Hard | Вызов инструментов |
|---|---|---|---|
| GPT‑5 | 89,2% | 92,5% | 94,1% |
| Claude 4.6 Opus | 88,6% | 91,0% | 88,7% |
| Gemini 2.5 Pro | 87,4% | 89,8% | 85,2% |
GPT‑5 заметно лучше для AI-агентов и многошаговых задач. Это закономерно — OpenAI давно оптимизирует свою линейку под структурированный вывод и вызов инструментов.
Длинный контекст
| Модель | Максимальное окно | Recall на 200K | Задержка первого ответа |
|---|---|---|---|
| GPT‑5 | 256K токенов | 87% | 4,2 с |
| Claude 4.6 Opus | 200K токенов | 96% | 6,8 с |
| Gemini 2.5 Pro | 2M токенов | 84% (на 200K) | 5,5 с |
Claude — лучший recall на длинном контексте. Это критично для работы с документами и Q&A по корпоративной базе знаний. Gemini — лидер по абсолютной длине окна, но в середине гигантского контекста точность падает (это известная проблема, признаваемая самой Google в её technical report).
Мультимодал — видео, аудио, изображения
| Модель | MMMU (мультимодал-бенчмарк) | Видео | Аудио (транскрипция + анализ) |
|---|---|---|---|
| Gemini 2.5 Pro | 75,0% | ✅ нативное | ✅ нативное |
| GPT‑5 | 73,0% | через DALL-E + Whisper | через Whisper |
| Claude 4.6 Opus | 67,0% | только статические изображения | ❌ |
Gemini здесь вне конкуренции. Если ваша задача — анализ контента с YouTube, разбор подкаста на сегменты, OCR из мобильных фотографий — это её территория.
Сравнение по 5 типичным задачам
Сценарий 1. Ревью кода для разработчика
HumanEval 92,1%, корректный вызов инструментов, отличная скорость. На простых функциях и однофайловых правках — ровно. На запутанном легаси иногда упускает контекст связанных модулей.
SWE-Bench 64,2% против 58,4% у GPT‑5 — лучший на реальных многофайловых багах. В 5× дешевле Opus при разнице в качестве менее 10%. По нашей статистике 60% задач разработчиков на RubikBot закрываются именно Sonnet.
Сценарий 2. Длинные тексты — лонгрид, white paper
Технически грамотный текст без литературной души. Подходит для отчётов, документации, описаний продукта. Звучит «функционально».
Лучший стилевой контроль среди всех моделей 2026. Может выдержать единый голос на 3000+ словах, понимает тонкие нюансы стиля бренда. Дорого, но для премиум-контента оправдано.
Сценарий 3. Анализ длинного документа — отчёт, контракт, книга
Контекст 200K, recall 96% — почти не теряет деталей. Лучший выбор для документов до 150 000 слов (примерно средняя бизнес-книга).
Единственный с окном 2 миллиона токенов. Это около 8 «Войны и мира». Расплата — на 1M+ recall падает до 84%, теряет детали в середине окна. Используйте только если документ реально не помещается в Claude.
Сценарий 4. Мультимодал — видео, аудио, изображения
Работает, но через композицию: для генерации изображений зовёт DALL-E, для транскрипции — Whisper. Каждый переход — отдельный круг и доплата за токены.
Нативно понимает видео, аудио и изображения на уровне текста. Один запрос — один результат, без промежуточных моделей. MMMU 75% против 73% у GPT‑5 и 67% у Claude.
Сценарий 5. Массовые задачи — чат-бот, классификация, перефразирование
90 ₽ за миллион входных токенов. 85% качества GPT‑5 на рутинных задачах. Лучший выбор если уже в OpenAI-экосистеме.
75 ₽ за миллион входных токенов — в 25 раз дешевле Claude Opus. В топ-5 по общему качеству. Для масс-чат-бота поддержки или массовой обработки тикетов — оптимум.
Цены в рублях через RubikBot
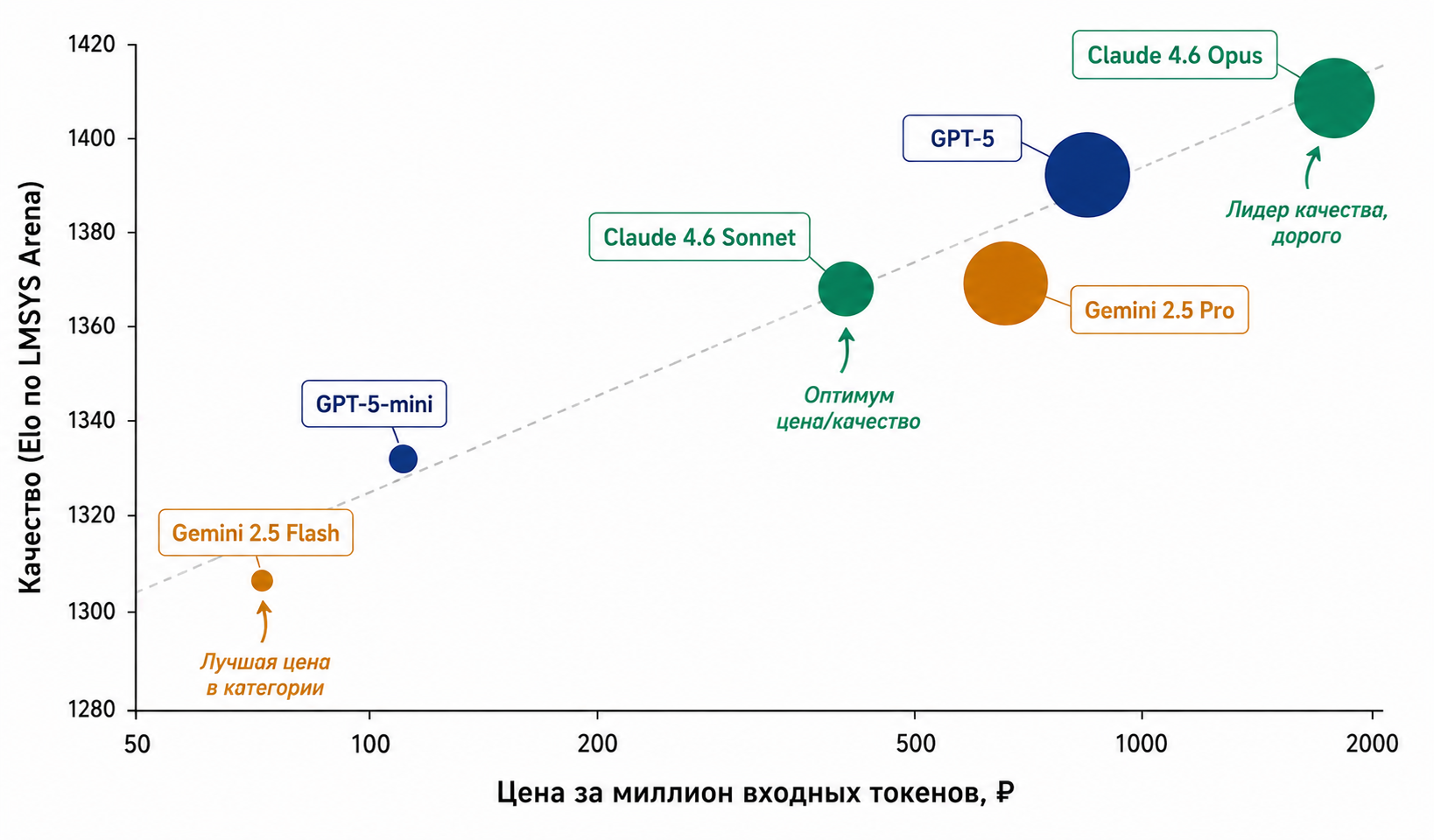
| Модель | Вход ₽/1М | Выход ₽/1М | Латентность |
|---|---|---|---|
| GPT‑5 | 850 | 6 800 | низкая |
| GPT‑5-mini | 90 | 720 | очень низкая |
| Claude 4.6 Opus | 1 900 | 9 500 | средняя |
| Claude 4.6 Sonnet | 380 | 1 900 | низкая |
| Gemini 2.5 Pro | 750 | 6 000 | средняя |
| Gemini 2.5 Flash | 75 | 600 | очень низкая |
Ключевой инсайт: mini- и flash-варианты покрывают 80% реальных задач за 5–25 раз дешевле флагманских моделей. Если ваша задача — не «решить олимпиадную задачу», а «суммировать письмо клиента» — берите младшую модель.
Подробный расчёт стоимости для четырёх типичных сценариев — в Цены на нейросети 2026.
Гибридная стратегия — не выбирайте одну модель
Самая частая ошибка — мысленно решить «у нас теперь GPT‑5 для всего» или «мы команда Claude». Это работало в 2024 году, когда был один достойный игрок. В 2026 году рабочий подход — роутинг между моделями:
- Рутинные шаги (классификация, перефразирование, чтение файлов) → GPT‑5-mini или Gemini Flash (90 ₽/1М)
- Тонкое рассуждение, сложный код → Claude 4.6 Sonnet (380 ₽/1М)
- Длинный документ или мультимодал → Claude Opus или Gemini Pro
- Вызов инструментов в агенте → GPT‑5
Hermes по умолчанию работает именно так — это его архитектурное решение. В config.yaml арендатора это выглядит так:
provider: openai
default_model: gpt-5-mini # для большинства шагов
fast_model: gemini-2-5-flash # самая дешёвая для классификации
deep_model: claude-4-6-sonnet # эскалация для сложных задач
context_model: gemini-2-5-pro # для документов более 200K токенов
agent_model: gpt-5 # для multi-tool агентных задач
Hermes сам решает, на какой шаг какую модель отправить — и экономит до 70% относительно подхода «всегда полный флагман».
Если вы выбираете модель «навсегда» — вы выбираете неправильно. Через 3 месяца выйдет следующее поколение, и расклад снова сдвинется. Гибридный подход через Hermes даёт переключаться на лучшую модель без переписывания приложения.
Что не учитывать при выборе
Четыре частых ловушки, в которые попадают новички.
- Бенчмарки от вендора. Каждый показывает свою модель лучшей. Берите только независимые: LMSYS Chatbot Arena, Artificial Analysis, SWE-Bench, MMMU.
- Старший номер версии. Не всегда лучше. Claude 3.5 Sonnet в 2024 был лучше GPT-4o; Claude 4.6 Opus сейчас лучше Claude 4.0 на агентных задачах, но не на простом ревью кода.
- Абстрактный размер контекста. Нужен recall на нужной вам длине, не просто 1М или 2М максимум. Gemini поддерживает 2М, но теряет точность на 1М+.
- Hype в социальных сетях. Реакция первых пользователей искажена эффектом новизны. Подождите 2–3 недели после релиза, посмотрите независимые бенчмарки.
Итоговая карта выбора
| Ваш контекст | Что брать |
|---|---|
| Разработчик, ревью кода, рефакторинг | Claude 4.6 Sonnet (баланс) или Opus (запутанный легаси) |
| Маркетолог, лонгриды, white papers | Claude 4.6 Opus для премиум, Sonnet для массового контента |
| AI-агент, многошаговая работа с инструментами | GPT‑5 для шагов планирования, GPT‑5-mini для рутины |
| Чат-бот поддержки, классификация, парсинг | Gemini 2.5 Flash (самая дешёвая) или GPT‑5-mini |
| Анализ длинных документов (200K–500K) | Claude 4.6 Opus |
| Гигантский контекст (более 500K) | Gemini 2.5 Pro (единственный вариант) |
| Мультимодал — видео, аудио, OCR | Gemini 2.5 Pro |
| Не знаете заранее | Hermes с гибридным роутингом |
Как мы тестируем модели в RubikBot
Внутри платформы каждые две недели прогоняем 50 наших внутренних тестов на всех моделях через единый API-эндпоинт. Метрики:
- Качество ответа (по 4-балльной шкале от двух ревьюеров)
- Латентность p50 / p95
- Стоимость запроса с фактическим числом токенов
Результаты публикуем в /research — раздел «Бенчмарки». Это нужно, чтобы и мы, и пользователи имели свежие данные именно по русским запросам — большинство публичных бенчмарков сделано на английском.
Что делать прямо сейчас
- Протестировать руками. /playground — переключатель моделей в шапке, 50 ₽ приветственного баланса хватает на 50–100 запросов. Запустите одну и ту же задачу через все три модели и сравните.
- Подключить к своему приложению. Зарегистрируйтесь, получите ключ API, поменяйте
base_urlв существующем коде наhttps://api.rubikbot.com/v1— и переключайтесь между моделями параметромmodel:. - Использовать гибрид через Hermes. Если ваш сценарий — автоматизация задач, а не одиночные запросы, активируйте Hermes — он сам выберет лучшую модель под каждый шаг.
Связанные материалы
Частые вопросы
Какая нейросеть лучше в 2026 году — GPT-5, Claude или Gemini?+
Claude 4.6 Opus или Sonnet — что брать?+
Gemini 2.5 Flash настолько дешевле — есть подвох?+
Чем разные модели открываются для одной задачи?+
Что брать если нужен длинный контекст — 500 000+ токенов?+
Как Hermes выбирает модель сам?+
Теги
Автор: Команда RubikBot